
At Kodecopter, our mission extends beyond basic chatbot solutions. We specialize in converting these data-rich PDFs into fully functional, interactive AI-driven chatbots. This transformation involves a multi-layered process, starting with robust content extraction and culminating in a highly intuitive user experience. By employing state-of-the-art machine learning techniques and LLM capabilities, our kodepilots ensure that each chatbot comprehends context, retains past interactions, and delivers precise, page-referenced responses that foster user trust and engagement.
1. From Static Content to Actionable Insights(Extracting and Processing PDF Data)
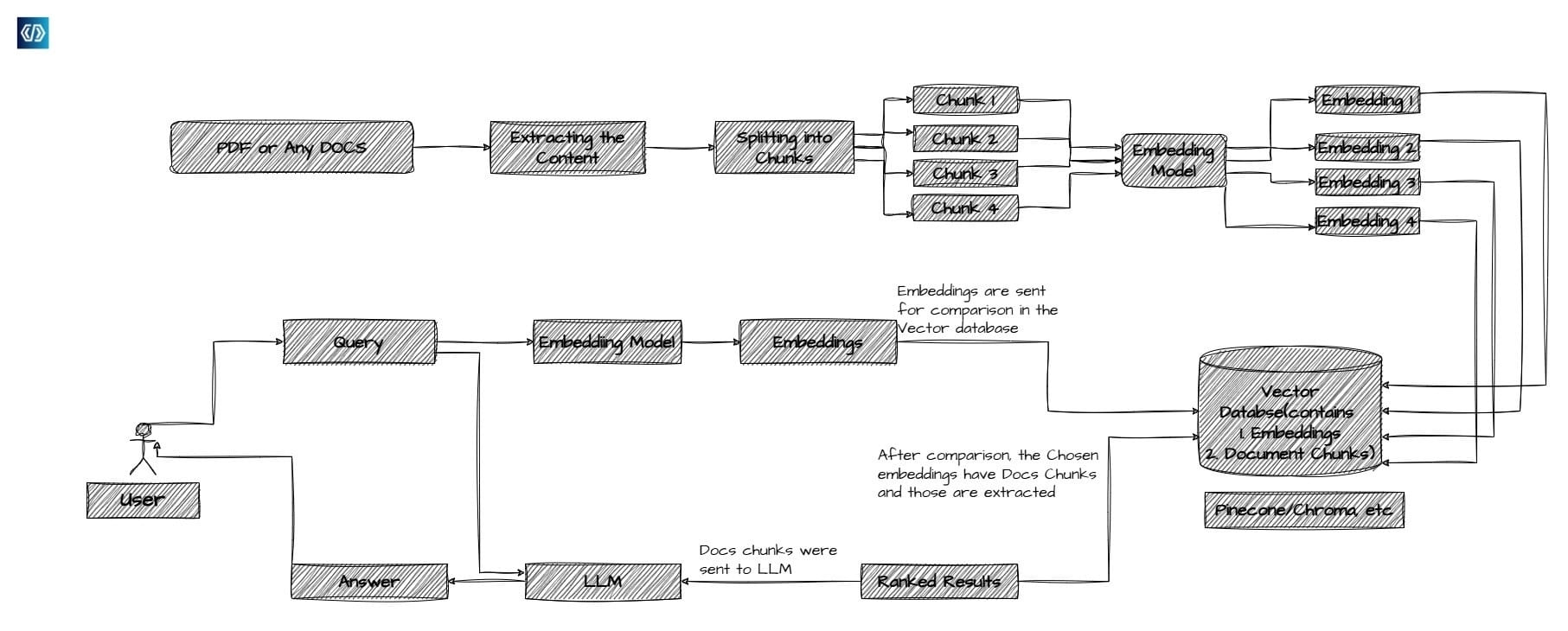
The process of creating an AI-powered chatbot from a PDF document begins with an essential phase: data extraction. This involves harnessing specialized tools such as PyMuPDF or PDFPlumber, which are designed to meticulously parse and extract textual content, tabular data, images, and metadata. Incorporating metadata, such as page numbers and section titles, empowers the chatbot to provide responses that are not only contextually accurate but also traceable to their original source, thus reinforcing credibility.
- PDF Parsing Techniques:
- Parsing occurs at both line-by-line and block levels to accommodate varying document structures
- Images and non-text elements are extracted and cataloged separately for potential visual reference in responses.
- Extracted text undergoes cleaning to remove extraneous line breaks, irregular spacing, and any non-standard characters that may disrupt data processing.
- Preprocessing Procedures:
- Normalization: This step ensures consistency by converting text to a uniform format, such as lowercase, and rectifying typographical anomalies.
- Tokenization: Text is segmented into tokens, facilitating the embedding phase where these units are analyzed for semantic meaning.
- Metadata Annotation: Embedding page numbers and section headings enhances the chatbot’s ability to attribute responses to specific parts of the PDF, ensuring users can verify information.
These preprocessing steps lay the groundwork for subsequent embedding creation, transforming static data into an actionable format that AI systems can utilize with remarkable efficiency.
2. Bringing Intelligence with Vector Databases(Embedding Creation and Vector Database Integration)
To render PDF content searchable and contextually aware, the creation of embeddings is imperative. Embeddings are high-dimensional vector representations of text, mapping sentences or paragraphs in a way that captures their semantic relationships. This process facilitates the AI’s ability to interpret user queries with an understanding that mimics human cognition.
Embedding Models:
- Utilization of Sentence Transformers or models from Hugging Face for transforming text into embeddings that reflect semantic depth.
- These models, built on the architecture of advanced neural networks like BERT (Bidirectional Encoder Representations from Transformers), are pre-trained on extensive corpora, ensuring that they grasp subtle language nuances.
- Feeding preprocessed text into these models yields vectors that represent contextual semantics, which are indispensable for intelligent chatbot functioning.
Integration with Vector Databases:
- Vector databases such as FAISS (Facebook AI Similarity Search) and Chroma serve as repositories for embeddings, supporting rapid, similarity-based searches.
- The kodepilots at Kodecopter meticulously configure these databases to sustain peak performance, even when housing thousands of vectors, ensuring that search operations remain expeditious and precise.
- This integration allows chatbots to return results with page references, enhancing user confidence through verifiable sources.
3. Developing a Context-Aware AI(Building the Conversational Model)
The core of an intelligent chatbot is the Large Language Model (LLM). These models are trained on vast, diverse datasets encompassing books, journals, and web content, allowing them to capture complex language structures and respond accordingly.
LLM Specifications:
- Models such as CTransformers or LLaMA are chosen for their robust ability to handle contextually rich queries with accuracy.
- These LLMs are designed with intricate transformer architectures, utilizing self-attention mechanisms to understand the intricate relationships between words and larger textual passages.
- Such models may feature millions or even billions of parameters, which enable them to internalize and process the multifaceted nature of human language.
Fine-Tuning and Prompt Engineering:
- The fine-tuning process involves training the LLM on specific interaction data to improve its responsiveness when referencing a vector database.
- Prompt engineering is used to construct precise inputs that guide the LLM in generating contextually relevant responses that may include page citations for user verification.
GPU Utilization for Enhanced Performance:
- Employing GPUs and libraries such as Torch significantly optimizes the training and inference phases, enabling real-time processing and handling high traffic scenarios without compromising performance.
4. Designing a Seamless User Experience(Deploying the Interactive Chat Interface)
The success of an AI-driven PDF chatbot is not solely dependent on its underlying architecture but also on the quality of the user interface (UI) and its ability to maintain context across interactions. At Kodecopter, we prioritize the development of intuitive and robust interfaces that cater to diverse user needs while ensuring ease of use and sophisticated functionality.
Frameworks and Tools:
- The chatbot’s front end is constructed using Chainlit, a powerful open-source framework that enables seamless UI creation and conversation management.
- Streamlit can also be employed for projects that require highly customizable, visually appealing interfaces, providing users with an interactive dashboard-like experience.
Contextual Memory Integration:
- One of the defining features of Kodecopters’ chatbots is their memory mechanism, which allows the chatbot to recall past interactions, thus maintaining conversational flow and providing personalized user experiences. This is achieved through techniques like conversational memory caching.
- Memory vectors are stored alongside embeddings, enabling the LLM to reference previous questions and answers, thereby building a coherent dialogue thread.
User Interaction Dynamics:
- The chatbot can be programmed to offer a range of responses, from simple answers to multi-layered explanations that can include hyperlinks back to relevant pages in the PDF or references that indicate specific page numbers for further reading.
- Users can initiate deep dives into content sections with follow-up questions, and the chatbot can navigate hierarchical content structures within complex documents, ensuring a thorough understanding of context.
Security and Data Privacy Considerations:
- Data privacy is paramount when developing chatbots, especially when handling sensitive documents or user information. Our solutions are designed with the following security layers:
- End-to-end encryption to secure data transmission.
- Access controls that ensure only authorized users interact with the system.
- Compliance with industry standards such as GDPR for data protection.
- Data privacy is paramount when developing chatbots, especially when handling sensitive documents or user information. Our solutions are designed with the following security layers:
5. Pioneering the Next Generation of PDF-AI Chatbots
The potential for PDF-driven AI chatbots extends across multiple sectors, revolutionizing the way information is accessed and utilized. Below are examples of how Kodecopter’s technology can be applied:
Corporate Training: Automating responses to frequently asked questions related to training manuals or HR guidelines within organizations, allowing employees to quickly access procedural documents.
- Education: Enhancing the learning experience by creating chatbots capable of answering questions based on textbook material or academic publications, empowering students with instant knowledge retrieval.
- Legal and Compliance: Providing lawyers and compliance officers with instant access to specific clauses or legal precedents within lengthy legislative documents.
- Healthcare: Assisting medical professionals by offering a fast way to query research papers, medical protocols, or pharmaceutical guides to support decision-making in patient care.
Advanced Feature Roadmap:
- Multilingual Capability: Expanding the LLM’s proficiency to handle queries and content in multiple languages, thereby making chatbot solutions accessible to a global audience.
- Voice Interface Integration: Implementing Natural Language Processing (NLP) models capable of real-time speech recognition, enabling users to interact with the chatbot through spoken commands.
- Enhanced Visual Data Processing: Incorporating Computer Vision capabilities to allow the chatbot to interpret charts and diagrams found within PDFs, thereby providing comprehensive explanations that include visual elements.
Continuous Learning and Upgrades: The future of AI-based PDF chatbots lies in their ability to continually evolve. At Kodecopter, we are committed to implementing continuous learning frameworks that enhance the chatbot’s ability to adapt to new data and improve over time. This ensures that our solutions remain not only technologically advanced but also user-focused, delivering maximum value to clients.
Conclusion: A Leap Towards Intelligent Document Management
The creation of a PDF-based chatbot involves a fusion of advanced technologies—ranging from text extraction and embedding generation to LLM integration and context-aware interfaces. Kodecopter stands at the forefront of this technological shift, enabling clients to unlock the true potential of their PDF documents and transform them into dynamic, interactive tools for information retrieval and user engagement.
As we continue to push the boundaries of document-based AI, we are committed to refining our methodologies, integrating new technologies, and building solutions that not only meet current needs but anticipate future ones. With advancements in multimodal processing, adaptive learning, and user accessibility, the possibilities for enhancing how we interact with and derive insights from documents are endless.